Understanding Technical SEO
SEO
Technical
A plain-English breakdown of the “Extracting Facts From Unstructured Text” patent and what it reveals about how search systems validate, score, and reuse content.
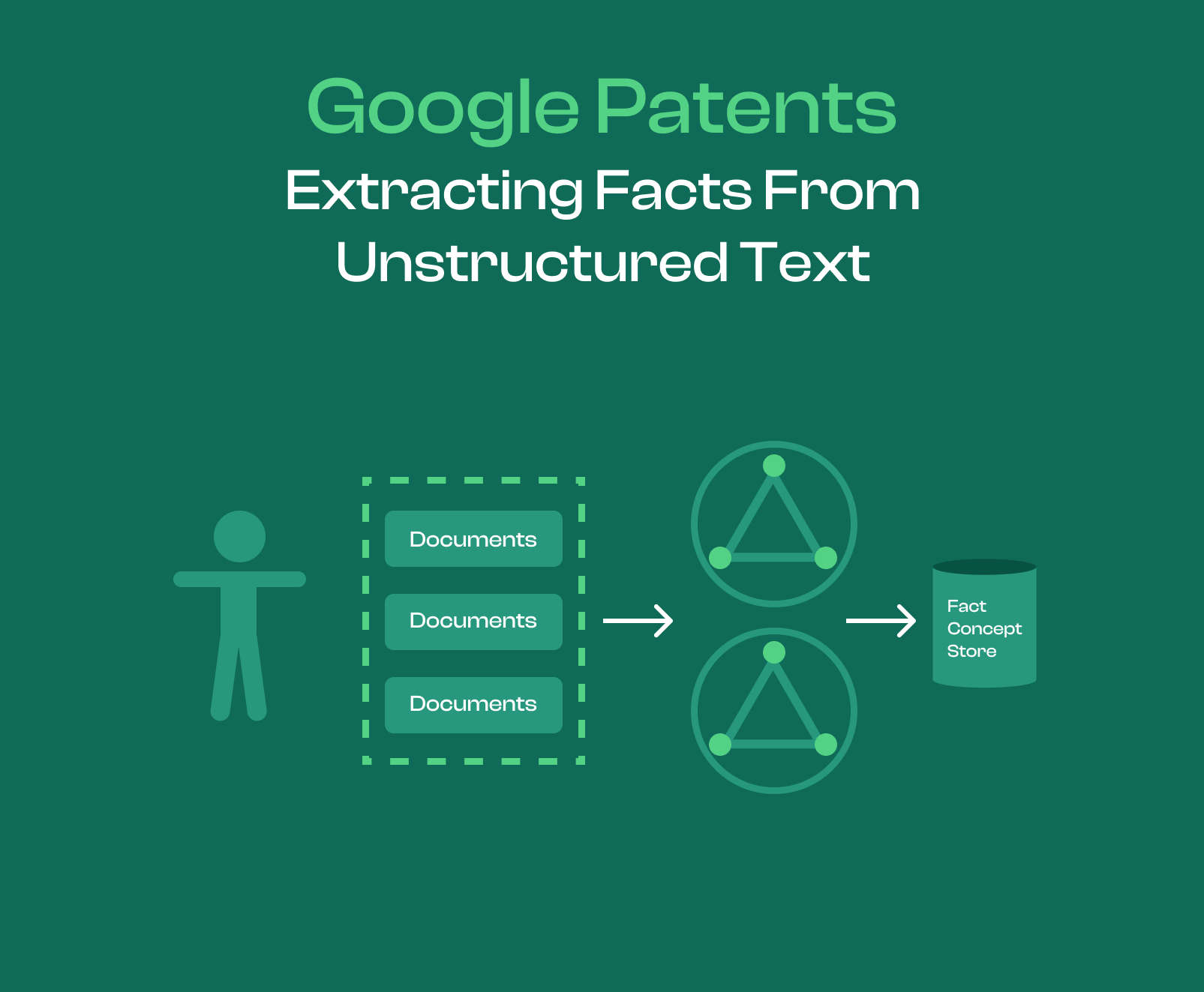
Search systems cannot reuse unstructured text as facts until the text is processed into structured representations that can be scored and stored. US 9,424,524 B2 describes a pipeline that extracts entities, topics, and facts from unstructured text and assigns confidence scores before storing them.
The system receives an electronic document that contains unstructured text. An example of this would be every page of your website. You can add semi-structured data on top of your website in the form of Schema, but the text on your website is considered ‘unstructured’ text.
The system extracts entities and disambiguates ambiguous entities to avoid attributing a fact or attribute to the wrong entity.
The system extracts facts by comparing text string structures to a ‘fact template database’. As the patent describes, the fact template database stores fact templates that include keywords tied to specific fact identifiers and keyword weights. The system links each extracted fact to extracted entities and topics, then computes a confidence score that indicates how accurate the extraction is likely to be.
Before we get too far ahead, a concept you have to understand is disambiguation. Disambiguation is the process that uses contextual clues to reduce ambiguity when associating extracted facts with entities. This is a system that commonly appears across multiple information extraction patents.
This patent describes various modules or systems that work together to understand the main entities being covered in your content, and eventually extract facts and information about each entity as well. Below we’ll go into a high level overview of how these modules or systems work together.
The entity extraction module of this system identifies entities mentioned in your content like people, places, organizations, etc. This entity extraction module can also disambiguate entities by comparing extracted entities and what is referred to as ‘co-occurrences’ against a growing knowledge base of co-occurring features. What this means is that your entities are compared against a database of information related to the entity you are mentioning. If what you are writing about is accurate to what is already stored on the topic, the system can confidently identify the entity you are mentioning.
Once the entity has been identified and given a high enough confidence score, another module, a topic extraction module, extracts one or more topic identifiers that represent the theme of your document/page. The patent then describes topic extraction techniques that compare keywords against topic models. The output is a topic identifier that is used to attach to facts for better association and validation.
A fact extraction module extracts a fact identifier by comparing your text string structures on your page to existing fact models stored in a database. The fact database stores sentence structures commonly used in this context, and keyword weights used to match those structures in new evaluated documents.
Relatedness estimation assigns confidence and controls storage
A fact relatedness estimate associates the entity identifier with the topic identifier and the fact identifier to calculate an overall confidence score. The patent describes confidence as being based at least in part on spatial distance in the text between both the fact and the entity. The patent also describes increasing confidence by using co-occurring entity identifiers in the same document or page. Meaning, if you keep facts and the entities they refer to close, and you use multiple contextual clues to reduce entity ambiguity, you will improve your confidence score, which increases the confidence score assigned to the extracted fact.
The patent describes the ‘fact template store’ as a database of reusable facts or sentence structures. The patent describes building templates by tagging documents to identify commonly used keywords, assigning weights to those keywords, selecting a fact template model with those keywords, and then using that model for future comparisons during extraction. With any entity there are certain attributes most commonly used to describe them, and those are the types of modifiers, contextual clues, and keywords that need to be present in your writing when covering them. In this template store there can be metadata like how frequently the sentence structure repeats across a multitude of documents and a confidence score associated with each sentence structure.
This patent directly describes how search systems go about detecting and understanding entities in your content. It describes that a page is easier to trust when its facts match stable, recognizable sentence structures and when those facts sit close to the entities and topics they describe. This patent describes confidence scoring that increases when a fact is physically close to the entity in terms of textual and spatial distance and topic signals that explain it thoroughly.
That means SEO is affected by whether your page makes references to your entity explicitly, meaning you leave no room for ambiguity in terms of which entity you’re discussing. It also means it is important that your page keeps facts near the entities they describe, and it’s also important that your page uses consistent fact-like sentence structures. Why, because those fact-like sentence structures will be easier to connect back to the entities you want to rank for, and fact extraction will be easier because you are being explicit about it.
The patent directly states that entity ambiguity reduces likelihood that these systems will accurately and confidently detect which entity you are writing about. If an entity mention is ambiguous, disambiguation must work before a fact can be reliably associated with the correct entity identifier. This means if you aren’t explicit you will force these systems to go through extra steps and run additional computations to determine what you should already have made clear for them. This then means you will not be given as high of a weight as you would otherwise have been given. In otherwords, the extracted facts will receive lower confidence scores and are less likely to be stored or reused by the system.
Some actionable steps you can take when writing your content to improve entity recognition and fact extraction will be covered below.
Your content should place entity mentions close to the facts that depend on those entities. The patent’s confidence scoring uses distance between extracted facts and extracted entities or topics, so distance control becomes a practical writing constraint.
Your content should avoid spreading the same entity across distant sections when you are making factual assertions about it. The patent describes co-occurrence and proximity as confidence inputs, so compact fact clusters around the correct entity reduce attribution risk.
Write facts as clear and asserted sentences rather than leaving the conclusions implied. The patent extracts facts by matching text string structures to existing fact templates, so sentences that look like commonly used fact structures already present in those templates are more likely to be extracted consistently across search and AI systems.
Your content should stay on topic and follow a logical progression within a document when you want facts to be associated with that topic. The patent discusses extracting identifiers related to your entity or topic, and it uses the content surrounding it to determine relevance. Meaning, if your content continually drifts off subject, you will reduce confidence even if individual sentences are well written and fact-focused.
The patent not only discusses a system that extracts facts, but that validates facts by comparing them to an existing database of related facts associated with the entities you are covering. The importance of this patent is that it explains how entities, topics, and sentence structures are evaluated together before facts are stored and used further.